Virtualization
About
This post discusses virtualization in general.
Kinds of Virtualization
Full
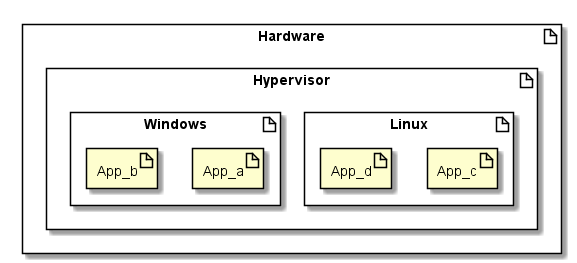
In full virtualization, the guest VMs binaries are unchanged. They run as user-level processes which is a different privilege mode than if it was run bare-metal. Due to this, the guest VM isn’t aware it is sitting on a hypervisor- so what happens if the guest issues a kernel-mode instruction?
Trap and Emulate Strategy
Since the guest isn’t aware of the hypervisor, it issues the kernel instruction as normal which generates a trap into the hypervisor to emulate. Though this gives the benefit of not requiring binary modifications on the guest operating system, there’s a draw-back.
Some privileged, or kernel, instructions may fail silently, i.e. from the guest OS perspective the instruction was handled as expected. To handle this case, the hypervisor must be cognizant of the set of silently failing instructions for each OS it supports and dynamically perform binary translation to appropriately handle said instructions.
Para
In para-virtualization, the guest VMs are aware they are running on the hypervisor. This obviously requires binary modification of the guest OS. We are still running against said guest OS from the applications concern.
How Much Modification?
Not much as documented by Xen’s proof of construction: 2,995 and 4,620 lines of code were modified for Linux and XP which is 1.36% and 0.04% of the total code base respectively.
Effort
In order to achieve virtualization, we’ll need to virtualize:
- Memory hierarchy
- CPU
- Devices
Lastly, we’ll need to add mechanisms handling data and control between guests and the hypervisor.
Memory Virtualization
Nothing significant with a guest operating systems CPU, TLB, physically tagged cache is required in virtualization. Handling virtual memory is, however.
Virtual to physical address mapping is the key functionality in memory management subsystems.
Remember that each process is under the illusion that its (virtual) memory elements are contiguous, when in reality they may be sparse in physical memory due to paging.
Guest To Hypervisor Translation
Each process in the guest VM has its own protection domain, and the guest VMs have distinct page tables they are aware of.
Guest Physical Memory Illusion
Let’s say we have a Windows and Linux guest running on our hypervisor. The total physical memory that the Windows guest thinks it has is \([0, n]\) and \([0, m]\) for the Linux guest.
Both the guests may think they have contiguous memory blocks, e.g.:
\(R_1 = [0, q]\) and \(R_2 = (q, n]\) for Windows and \(R_1 = [0, l]\) and \(R_2 = (l, m]\) for Linux.
However these blocks may be mapped to non-contiguous blocks on actual, physical machine memory.
Shadow Page Tables (SPT) & Machine Page Numbers (MPN)
In a non-virtualized setting, the page table is the broker when the process requests a translation from a virtual page number to a physical page number.
Virtualized settings need another level of indirection between the translation of the physical page number (PPN) and MPN: the SPT.
The separation of concerns is:
- Guest PT translates VPN to PPN.
- Hypervisor SPT translates PPN to MPN.
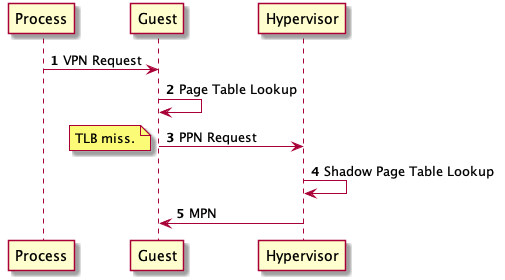
In T1 hypervisors, the SPT is managed by the hypervisor, but in T2 it could be managed in either the guest or hypervisor.
In typical architectures, translating a virtual address (VA) is as follows:
- CPU checks TLB (cache) to see if the VA has already been translated (hit).
- If so, simply return the MPN (e.g. physical address) from cache.
- Otherwise, we have to make a trip to memory and do a PT lookup.
In the virtualization world, the SPT lookup is analogous to the PT lookup.
Efficient Mapping
Full Virtualization
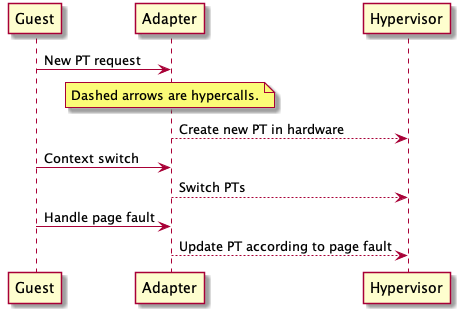
It is more efficient for the hypervisor to trap the guests PT lookup and have the hypervisor introspect its SPT for the translation. Now, we can translate a user-level processes VPN to MPN by just consulting the SPT. This can be accomplished by hypervisor mechanisms supported by TLBs and hardware page tables. VMwares ESX server implements this.
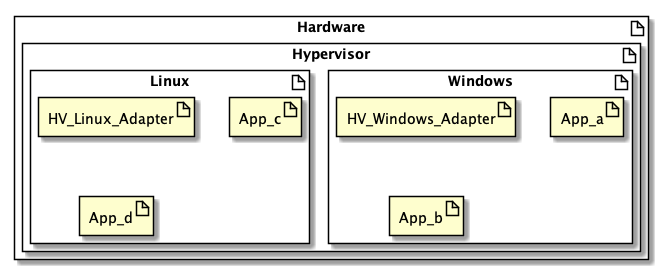
Paravirtualization
In this setup, the guest knows about the hypervisor, so some of the burden of efficient mapping can be shifted to the guest. The PPN to MPN mapping is now managed by the guest via the hypervisors hypercall API.
Dynamically Increasing Memory
How do does the hypervisor handle surges in memory consumption from the guests? Keep in mind that there’s a cap on physical main memory that is potentially being shared among guest VMs.
Naive Approach
Rob Peter to pay Paul!
With this approach, the hypervisor forcibly steals a chunk of a guests physical memory and grants it to another guest that is in need of more memory. This sudden drop of physical memory in the guest can lead to unexpected behavior on the guest.
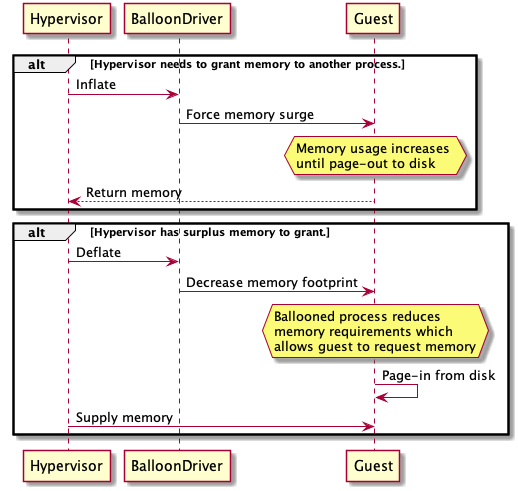
Coaxing Approach (Ballooning)
The novel idea here is the hypervisor installs a special device driver, called the balloon, into each guest OS:
Now the hypervisor has a private channel to each guest, via the balloon driver, to dynamically coax the guests to balloon or deflate their memory usage.
Sharing Memory Across Guests
What if we have duplicate guest OS’s that are running the same kind of user-level processes- can these guests share physical memory?
This can be achieved by mapping the duplicate guest OS page tables into the same MPN. This aids in avoiding duplication.
The hypervisor must have a mechanism where it can tell its guest VM which pages to mark as copy-on-write (COW)
As soon as either guest OS needs to write-to its shared page, the hypervisor can simply copy the guest OS memory to another physical location.
Guest-oblivious Page Sharing
This method is used in VMwares ESX server. At a high level, it uses a structure called a hint-frame with the following metadata:
- Hash obtained from a guest VM page contents.
- VM identifier.
- PPN from the VM.
- MPN from main, physical memory on the host.
- Refs- a counter of how many VMs share this MPN.
Although we have this hint-frame data structure, we cannot rely on it to compare two physical pages from different VMs. To do so, we can use two matching hint-frames and do a full comparison.
If the full comparison results in a match, we:
- Increment
Refscount to two in the hint-frame the two VMs are now sharing. - We then mark the guest VMs pages as COW, so that their pages will map to a copied physical page on write in order to maintain integrity.
- Finally, we can free up one of the physical page frames.
These mechanisms are ideally run as daemon processes. This approach is completely abstracted away from our guest VMs and applicable to full and paravirtualized hypervisors.
Memory Allocation Policies
Pure Shared-Based
You get what you pay for.
E.g., based on the SLA you have with some data center, they provide resources commensurate with the dollar amount you pay. A downside to this approach is holding- some VM could hog up the resources and not use them which could be a waste.
Working-set (Elastic?)
If the working-set of a VM increases, you give it more memory. If the working-set decreases, reclaim the memory for another VM.
Combined (Dynamic Idle-adjusted Shares)
Tax idle pages more than active pages.
If a VM has high memory utilization, good! Otherwise, its probably idling and should be taxed or penalized. This means we will slowly reclaim memory that the VM will probably not notice is gone anyways since it was idle.
The tax-threshold set is up to the policy creator. E.g., say the threshold is 50%. If some VM is idle, then there’s a 50% chance its memory will be taken away. Some middle-ground is probably the best approach.