DRAM Disturbance Errors and RowHammers
About
A summary on required DRAM disturbance errors and how bits are flipped in memory without accessing them and Project Zero exploits of such errors.
Memory isolation is key in the TCB.
Memory access in one location shouldn’t have unintended side effects on data stored in other addresses.
This isolation is harder to achieve as DRAM technology scales down. It’s proved that reading from the same address in DRAM can corrupt nearby data. This disturbance error is caused by charge leakage from repeatedly toggling DRAM word-lines.
The DRAM goal of scaling down has an advantage of reducing cost-per-bit of memory. This sacrifices memory reliabilities due to:
- The smaller the cell, the less charge it can hold, making it more vulnerable to data loss.
- Close cell proximity causes undesired interaction.
- Higher variation in process technology increases outlier cells that are very susceptible to cross-talk, making the previous points worse.
These factors contribute to disturbance- different cells interacting with each other’s operations. Once this disturbance breaks the cells noise margin, its malfunction is called a disturbance error.
The Word-line
The root cause of DRAM disturbance errors are due to voltage fluctuations on an internal wire called the word-line.
A DRAM is a 2-d cell array, and each row has a word-line.
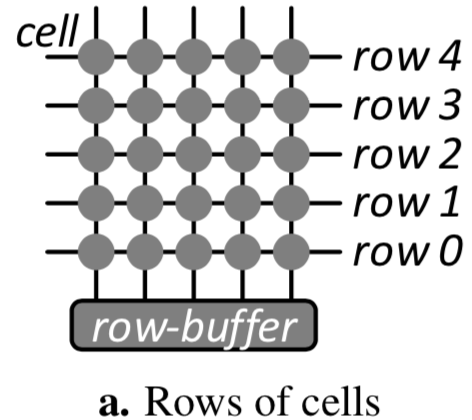
Accessing a cell in a row requires activating its word-line by raising its voltage. Multiple row accesses causes the word-line to toggle repeatedly, which causes voltage fluctuation, causing the disturbance error on neighboring rows.
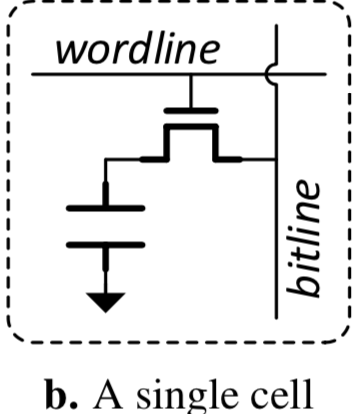
Each cell is an intersection of the vertical bit-line and horizontal word-line, connecting all cells in the grid.
Inducing Disturbance
A
This snippet generates a DRAM read on every data access. It queues up multiple DRAM read requests.
code1a:
// read from DRAM @ address X into general purpose register
mov (X), %eax
// read from DRAM @ address Y into cache register
mov (Y), %ebx
// Evict data from cache
cflush (X)
cflush (Y)
// Ensure data is fully flushed
mfence
// Loop
jmp code1a
The key observation is that X and Y are chosen such that they map to the same bank but different rows within the bank. This code forces the memory controller to open and close repeatedly, for millions of iterations. This causes unintended bit-flips, or writes, when no write was issued- this proves the cause of the disturbance error.
B
code1b:
mov (X), %eax
cflush (X)
mfence
jmp code1b
This does not cause the disturbance error, since all reads target the same row in DRAM. The memory controller minimizes DRAM commands by opening and closing rows just once.
DRAM disturbance errors are caused by repeated toggling of a row, NOT by column reads- which is exactly why code B doesn’t induce errors.
Bad News
Such disturbance errors violate two memory invariants:
- Read access should not modify data at any address.
- Write access should modify data only at the address being written to.
Violating such invariants, such as inducing disturbance errors, opens up avenues for error injections, system crashes, and hijacking.
Privilege Escalation Exploit
The Project Zero team from Google exploited disturbance errors to cause bit-flips in page tables. This enabled a user-level process to gain read and write access to all physical memory, something the team argues could have been discovered sooner had vendors been more explicit about this unreliability bug.
Their kernel-privilege exploit by row-hammering to induce a bit-flip in a page table entry (PTE). This causes the PTE to point to a physical page containing a page table of the attacking user-level process. The attacking process now has access to one of its own page tables, hence all of physical memory.
Ensuring High-Probability of Attack
- Row-hammer induced bit-flipping tends to be repeatable. With this property, we know which bit location will be fruitful for exploiting.
- As a PTE’s PPN changes, there’s a high probability it’ll point to a page table of the attacking process. To trigger such changes, they spray most of physical memory with page tables. Spraying can be done by calling
mmapon the same file repeatedly. This is fast, 3 gigabytes of memory full of page tables takes about 3 seconds!
Exploit Steps
mmapa large block of shared-memory segments in/dev/shmrepeatedly.- Search block for victim addresses by row-hammering random address pairs. Or, treat
/proc/self/pagemapas a cache of victim physical addresses from a previous run. - If victim address was bit-flipped with no benefit for the exploit, skip that address set.
- Otherwise,
munmapall but the aggressor/ victim pages and begin the exploit attempt.
Terrifying News
Could this exploit be done in normal memory accesses? The Project Zero thinks so, if all cache levels generate misses to allow for the row-hammer bit flipping.
If possible, it’s a serious problem, because now JavaScript code can generate bit flips on the open web, perhaps via JavaScript typed arrays.
Solutions
- Make better chips- regardless of improved process technology, the goal is still for smaller cells, which makes disturbance errors possible again.
- Correct errors- too expensive, especially for consumers.
- Refresh all rows frequently- causes performance degradation and energy-efficiency, however the paper discusses implementation that could make it worth it.
- Retire cells (manufacturer)- victim cells to replace could take days.
- Retire cells (consumer)- end-user has to pay cost of finding such victim cells.
- Find “hot” rows and refresh neighbors- heuristic approach to identify frequently opened rows and refresh only their neighbors. Intuitive, but introduces hashing, which introduces hash collisions.
- PARA- the proposed solution. When a row is toggled, one of its neighbor rows is also opened with low probability, i.e. refreshed. The main advantage is that it is stateless and doesn’t need expensive hardware counters. PARA has small performance impact for strong reliability and low design complexity from its stateless nature.